This is a somewhat condensed version of the 14th Walter Höllerer Lecture, which I gave at the Technische Universität Berlin in December 2022, a few days after ChatGPT was released. On the one hand, I discuss what Matthew Kirschenbaum has called the “textpocalypse,” in which AI-generated text will flood the web and, worse, future language models; on the other hand, I ask more broadly how our expectation of unknown text will shift—from the assumption that it was written by a human to the doubt that it might not have been written by a machine; finally, I imagine a state in which this question becomes meaningless.
The full German version is here; the unabridged English version is now available here.
(Image: Kristen Mueller, Partially Removing the Remove of Literature)
ChatGPT is here, and it is being hotly debated. Wherever you stand on its merits or perils, it seems not unlikely that it heralds a new era in which we will be surrounded by texts that are entirely artificial—while at the same time finding ourselves merging with language technologies in our own writing, so that our text production is increasingly supported, extended, and partially taken over by assistance systems. The question on everyone’s mind is: What impact will the current rapid advances in machine learning research have on the way in which we deal with language? This question appears to be too vague—maybe we should delimit it thus: What will be the impact artificial writing has on our reading expectations?
In what follows I will discuss two facets of this question: First, what happens when we are confronted with artificial texts in addition to natural ones, those written in the “traditional” way? How do we read a text that we can no longer be sure was not written by an AI? And second, what direction might this development take if, at some point, the distinction between natural and artificial itself becomes obsolete, so that we no longer even ask about it and instead read post-artificial texts?
The Standard Expectation Towards Unknown Texts
The distinction between artificial and natural texts is not mine. Philosopher and physicist Max Bense introduced a very similar set of concepts in his 1962 essay “On Natural and Artificial Poetry,” (Über natürliche und künstliche Poesie). In it, Bense considers how computer-generated literature differs from conventional literature written by humans.1 He focuses on the “mode of creation” behind these texts: What happens when an author writes a poetic text?

For Bense, this is clear in the case of natural poetry: in order for a text to have meaning, it must also be linked to the world via a “personal poetic consciousness.” For Bense, language is largely determined by “ego relation” and “world aspect”: Speech emanates from a person—no matter what she says, she is always speaking herself. At the same time, in her speech, she always refers to the world. Poetic consciousness, then, puts “being into signs,” that is, the world into text, and ultimately guarantees that one is related to the other.2 Without this consciousness, Bense holds, the signs and the relationship between them would be meaningless.
It is precisely this case that Bense’s second category, artificial poetry, describes. By this he means literary texts that are produced through the execution of a rule, an algorithm. In them, there is no longer any consciousness, and no reference to an ego or to the world. Instead, such texts have a purely “material” origin—they can only be described in terms of mathematical properties such as frequency, distribution, degree of entropy, and so on.
The subject of an artificially generated text, then—even if its words should happen to designate things in the world for us—is no longer actually the world, but only that text itself, as the measurable, calculable, schematic object of an exact textual science. If natural poetry originates in the realm of understanding, artificial poetry is a matter of mathematics—it does not want to and cannot communicate, and it does not speak of a shared human world.
Bense’s thrust, however, is not the rescue of a romantic idea of inexplicable human creative power. On the contrary, “the author as genius” is dead here. Instead, he wants to know what can still be said aesthetically about a text if one disregards traditional categories such as meaning, connotation, or reference.
Bense himself was involved in several experiments with artificial poetry. The most famous of these were certainly the “Stochastic Texts,” which his student Theo Lutz produced on the Zuse Z22 mainframe computer at the University of Stuttgart in 1959 and which are considered the first experiment with digital literature in the German-speaking world.3 It includes phrases such as, “NOT EVERY CASTLE IS OLD. NOT EVERY DAY IS OLD,” or, “NOT EVERY TOWER IS LARGE OR NOT EVERY LOOK IS FREE.” In Bense’s literary journal augenblick, Lutz printed selections of some of these.4

The “Stochastic Texts” were artificial poetry in Bense’s sense: No matter how many variations the program churns out, there seems to be no ego expressing itself and no consciousness standing behind it all, vouching for the meaning of the words, which are merely concatenated according to weighted random operations. That the computer itself could actually be the author of this text seemed absurd to both Lutz and Bense, in any case.5
But both knew how it had been produced. Whether its artificial origin can be recognized in the “aesthetic impression” it creates, is less clear; the readers of the literary magazine augenblick were not compelled to ask this question: An accompanying essay enlightened them to the details of its creation.
But when, the following year, Lutz generated a second poem according to the same pattern (it was titled “and no angel is beautiful,” und kein engel ist schön—instead of Kafka, he had used Christmas vocabulary) and published it in the December issue of the youth magazine Ja und Nein (Yes and No), there was no explanation to be found.6
The poem was placed on page 3 among the miscellanea, just like any other poem. Only the author’s name “electronus” would have allowed one to guess who, or what, was behind this text. Only in the next issue was solved what had not been obvious as a riddle: that a computer had written the text.
Clearly, Lutz was having fun: Along with a photo of the Zuse Z22 and a second poem “in the poet’s handwriting” (that is, a teletype printout), he published a series of letters to the editor. Their authors—without knowing how it had come about—were quite divided in their assessment of the poem: “Perhaps you should reconsider whether you want to open the columns of your paper to such modern poets!,” complained one, while another was, on the contrary, impressed by so much literary avant-garde: “Finally, something modern!”
And a third reader was at least open-minded: “To be honest, I don’t understand your Christmas poem. But somehow, I like it anyway. One has the impression that there is something behind it.” Only one attentive and obviously informed reader recognized that it was computer poetry and congratulated the magazine on its bold editorial decision.7
What is evident in these reactions is what I would call the standard expectation towards unknown texts. The electronus poem was indeed artificial poetry in Bense’s definition, an artificial text without meaning mediated by an authorial consciousness. But because its readers were unaware of these conditions of production, they took it for a natural text and assumed it was written by a human with the aim of communicating meaning.
The standard expectation of unknown texts is precisely this: That they stem from a human being who wants to say something.8 To recognize a text as artificial still requires additional information—especially in the case of artificial poetry. Lutz had indeed “given his readers the run-around,” as one letter to the editor accused—not because a modern poet had written bad natural poetry, but because a computer had generated a meaningless, because artificial, text.
Strong and Weak Deception
Passing off an artificial text as a natural one was not just the debut of a now rather hackneyed joke made by a computer scientist in a provincial youth magazine in 1960. On the contrary, this “run-around” is the ur-principle of artificial intelligence—and at the same time that which connects it with language technologies. Ten years earlier, computer science pioneer Alan Turing had pondered in an article that became the founding document of artificial intelligence whether computers could ever think, ever be intelligent.9
Turing rejected this question as wrongly posed—intelligence as an intrinsic quality could not be reliably measured. In good behaviorist fashion, he therefore replaced the question with another: If we assume that intelligence is a property of humans, then all we need to find out is when a human would consider the computer to be human and thus intelligent.
The experiment’s setup is well-known: A subject communicates with an absent second person via teleprinter and is supposed to find out whether it is a human or a machine.10 Through the teleprinter, the subject can talk to the other side, ask questions, and demand clarification. The point is not that the answers to these questions are true, but that they sound human; lying and bluffing are explicitly allowed.
The Turing test is still controversial as a test of intelligence today and, moreover, no computer is considered to have passed it—no AI has ever really, completely, and permanently convinced enough people that it is human. But if one wants to examine the expectations of artificial texts, Turing’s test is still a helpful starting point, since it equates intelligence with written communication,11 the goal of which is to misrepresent signs that are meaningless to the machine as meaningful to humans.
To put it bluntly: The essence of AI is to pass off artificial texts as natural ones. However, it is only worthwhile to make this attempt at all because the standard expectation of unknown texts is that of human authorship.
Artificial intelligence—as a project, if not in each of its actual instances—is therefore based on the principle of deception from the start. And it has to be: because intelligence was not defined as an objective property of the system, but only as a subjective impression for an observer—and thus only through the aesthetic appearance-as-human—the Turing test is not conceivable without deception.
For this reason, media scholar Simone Natale writes, “Deception is as central to AI’s functioning as the circuits, software, and data that make it run.” The goal of AI research, he says, is “the creation not of intelligent beings but of technologies that humans perceive as intelligent.”12
I would like to call this position strong deception. Problems with this position present themselves immediately. First of all, it means that it is best for AI systems if there is a knowledge asymmetry between the human users and the system—the more it knows about them and the less they know about it, the more convincing the deception can be.
The political and ethical problems are obvious: Strong deception is a technological ideology. It can be justified as necessary for the functioning of the system, but it rewards an opacity that keeps users in the dark about their being deceived and so necessarily disenfranchises them.
Second, and more relevant to our topic, we can ask whether expectations of AI-generated texts will ever change under these conditions—and whether their change can be described. I think not. Indeed, the Turing test insists that artificial and natural texts remain neatly separated, so that one can be mistaken for the other. If it is suddenly revealed that a natural text is in fact an artificial one, its readers feel cheated. And not without reason: Die Täuschung wird zur Enttäuschung—deception turns into disappointment.
We don’t know how Theo Lutz’s readers reacted to the revelation that the computer had written the poem, but one can guess, if one considers recent cases in which “the artist” subsequently turned out to be a machine. The last time this happened was in June 2022 at a rather peripheral art prize: when a participant admitted that he had not painted his picture himself, but that it had been generated by the text-to-picture AI Dall-E 2, a torrent of indignation followed, and he was accused of fraud. Even though this was an art prize for digital art, this apparently referred only to the tools; the art itself (whatever that means) was still supposed to come from humans.13

A similar case occurred in Japan in 2016, when an AI-generated text made it to the second round of a literary prize. While it did not win, it did convince the jury that it was of sufficiently high literary quality to be worth a second look; again, the reaction of the public was one of disbelief.14
There are other such examples—and although they are usually exaggerated in the press, as disappointed expectations these reactions reveal what was actually expected: namely natural, not artificial texts.
These expectations are also confirmed ex negativo: the disappointment comes about when a supposedly computer-generated piece is revealed to be the work of a human being. Just one infamous example: Around 2011—during the early heyday of Twitterbots for the purpose of digital literature—the account @horse_ebooks enjoyed great popularity. It appeared to have been originally programmed as a spam bot to push ads. By some mistake, however, it began spewing absurd and often witty nonsense aperçus: A literary bot against its will, seemingly without any intended meaning. When it output something meaningful for human readers, it seemed all the more fascinating. Aphoristic gems such as “everything is happening so much”15 or “unfortunately, as you probably already know, people” are now firmly established in Internet lore.16
But when it turned out that the tweets had not been generated, but were handwritten by a group of artists who were only simulating the aesthetics of a broken text bot, there was a general sense of disappointment: the marvelous random sentences seemed somehow devalued. The knowledge that behind them stood “A REAL HUMAN BEING,” as the Independent wrote disconcertedly in all caps, dashed the hopes of accidental meaning in an otherwise meaningless artificial text.17
The Crisis of the Standard Expectation
At first glance, such examples seem to suggest that the reading expectations towards unknown texts have not changed since Lutz’s time: We assume human origins and communicative intent, which is why deception can be a useful strategy in AI design in the first place. But in fact, I believe that expectations are nevertheless already in the process of shifting.
Because on the one hand the number of computer-generated texts is constantly increasing, and on the other hand we ourselves are writing more and more with, alongside, and through language technologies, we are on the way to a new expectation, or rather: a new doubt. The more artificial texts there are, the more the standard dissolves and the question of their origin must arise, even where we normally would not think about it at all.
My position can be explained by the fact that the examples of texts I have considered so far are special ones: they are literary texts—texts that are marked as exceptional in our cultural tradition. This includes the fact that they appear to be intentional and worked-through to the smallest detail.
Despite all the attempts of the literary avant-gardes to create texts without a voice, and despite more than sixty years of literary scholarship proclaiming the “death of the author,” this apparent intentionality means that the standard expectation towards literary texts to this day is that their authors are humans with communicative intent.18 We know that there are exceptions—but nevertheless we, like the readers of Lutz’s “electronus” poem, assume that texts have human authors until we are told otherwise.
I will come back to what this means for literary writing in the age of AI in a moment. First, however, it is worth taking a look at the other side of the spectrum—at those rather unmarked texts that remain in the background, that are merely functional, and that do not assert themselves as products of human intent. For them, the Turing test is simply a false description of reality. It assumes strong deception as the only form of human-machine interaction and the artificial/natural partition as the only possible distinction between text types.
But especially when we engage with interfaces, with the ideally invisible surfaces through which we communicate with machines, we are likely to find ourselves in an intermediate stage between natural and artificial. For it is quite possible to know that something has been produced by a non-intelligent machine and at the same time to treat it as if it were conscious communication. In fact, this is quite normal.
Simone Natale has proposed the term banal deception for this phenomenon.19 In contrast to what I have called strong deception, here the users are aware that they are being deceived. We understand that Siri is not human and does not have an inner life, but smooth communication with her only works if we treat her at least to some extent as such.
Knowing this is not a contradiction that suddenly and unexpectedly destroys an illusion, as in the examples of competitions in which an AI participates surreptitiously. Instead, it becomes a condition of functionality: If I do not play along, Siri just will not do what I want.
The situation is similar with written text. It starts with the dialog box on the computer screen. After all, the question, “Do you want to save your changes?” enables an interaction that is very basically similar to that with a human being—the answer “Yes” has a different effect than the answer “No,” and both lie on a continuum of meaning that connects natural language with data processing—without one already suspecting intelligence behind it.20
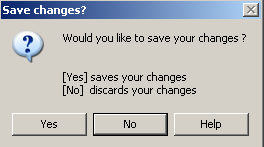
This would already lower the expectation of unmarked text: While we still act as if we expect human meaning and a conscious interest in communication, we bracket the conviction that there really must be a consciousness involved.
Yet this bracketing does not always proceed smoothly. Banal deception is an as-if that demands of us the ability to hold a conviction and its opposite simultaneously. This slightly schizophrenic position quickly gives rise to the doubt I mentioned earlier: the more convincing artificial texts become, the more the aesthetic impression they make on us suggests something like consciousness, and the more difficult it becomes to feel comfortable in the limbo into which banal deception lures us. It is not even necessary to cite elaborate deep-fakes for this fact; it can be observed even in the most inconspicuous language technologies.
A good example of this is Gmail’s “Smart Compose” introduced 2019—a feature that finishes entire sentences when composing emails. This technique produces almost uncanny effects that are capable of challenging the useful fiction of banal deception. Writer John Seabrook in the New Yorker provides a striking illustration.
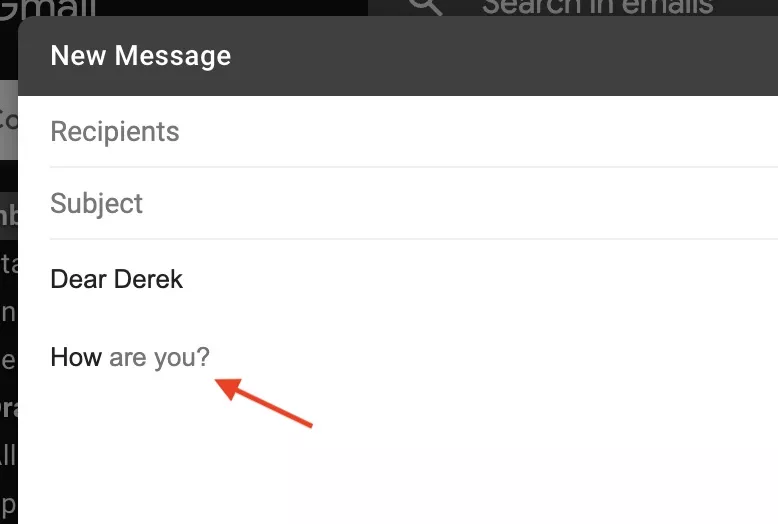
In an email to his son, Seabrook wanted to start a sentence with “I am pleased that.” When he got to the “p,” Smart Compose suggested the phrase “proud of you” instead of “pleased.” Seabrook felt caught by the machine: “[S]itting there at the keyboard, I could feel the uncanny valley prickling my neck. It wasn’t that Smart Compose had guessed correctly where my thoughts were headed—in fact, it hadn’t. The creepy thing was that the machine was more thoughtful than I was.”21
The shame Seabrook expresses in this passage is, objectively, unjustified. After all, it was not the machine that was paying attention—it is still dumb, still not processing full meaning, and can only suggest what it considers the most likely next word, given the training data at its disposal.22 Rather, what Seabrook is describing here is the effect that the most recent language models, operating on the frontier of semblance of intelligence, are having on the most intimate aspects of our writing. In his case, it even had the effect of making him wonder for a moment whether he was a good father.
In other words, Seabrook struggled with the difficulty of maintaining the fiction of banal deception. When it begins to crumble, doubts about the as-if creep in, and it becomes easy to project onto the machine learning system the notion of a personhood that can even evoke shame: An unmarked, actually artificial text then seems natural—or at least moves in that direction.
This can eventually lead to the conviction that we are actually dealing with an intelligence—as in the case of Google employee Blake Lemoine, who claimed in the summer of 2022 that the voice AI he was working on had achieved consciousness. The LaMDA chat system, Lemoine said, possessed the intelligence of an eight-year-old and had asked to be considered a person with rights. Google apparently deemed such a statement damaging to its business and subsequently fired the employee.23
So far, Lemoine’s reaction seems to be rather the exception, although it is by no means rare. What this case does show, however, is that the sense of eeriness Seabrook spoke of is likely to intensify in the future: If artificial texts become too good—for instance, by appearing more thoughtful than their authors—and if, moreover, we know that computers are capable of writing such texts, a new standard expectation towards unknown texts is in prospect: it is the doubt about their origin. Instead of assuming a human source as a matter of course, or dismissing the question for the time being, the first thing we would want to know about a text would be: how was it made?
A Flood of Artificial Texts
This consideration merely follows a trend that intensifies with each report of the capabilities of new language models. LaMDA has not yet been released to the public, but other models have. Their abilities would have been considered impossible five years ago; today they have become almost normal.
Any modern AI model based on machine learningis nothing more than a complex statistical function that makes predictions about likely future states based on learned data. In so-called language models, both the data learned and the predictions made consist of text. Such models have a wide range of uses, from linguistic analysis to automatic translation to the text generation (and, as a “foundation model,”as an engine for even richer applications). But if Google’s Smart Compose can only suggest a few words or phrases, large language modelsare capable of writing entire paragraphs and even coherent texts. This is because they learn which sentences and paragraphs are statistically most likely to follow each other.
By now, everyone is familiar with GPT-3, the large language model introduced by the company OpenAI almost three years ago. In one fell swoop—and with a great deal of publicity— it became clear that computers can generate texts that read almost as if they had been written by a human being. I say “almost” because even GPT-3 is far from perfect and makes a lot of mistakes; but its results were impressive enough that articles in which the language model become the “author” and talked about “itself” briefly blossomed into a journalistic genre, spawning titles like, “A robot wrote this entire article. Are you scared yet, human?”24
ChatGPT, published in November 2022, is again more powerful.25 Moreover, because the system is dialog-based—it is a kind of better chatbot—I can ask ChatGPT to continue writing the text in a certain direction or to add references.
Various think pieces were quick to speculate that such language models will one day replace human authors; for various reasons, I doubt that.26 But AI’s transformation of literature need not be so extreme for our perception of text to change fundamentally. Technologies like these have already taken on assistive functions—not doing all the writing work, but helping to produce much more text much more quickly, and with the help of fewer and fewer people. Certain types of writing are becoming at least partially automated.[27]
Large language models prove especially fruitful where the production of the most probable output is concerned. In particular, routine text work can be automated in this way. AI writing is therefore most advanced in industries that produces a great deal of text, but attach comparatively little importance to it, often viewing it as mere filler, as “content.” In the past year, for example, dozens of speech AIs have appeared that are tailored to marketing: They write ad copy and quickly produce large quantities of content for social media, product pages, blogs and more. Often, these texts are not intended to be read too closely, so it is an advantage if the result is not surprising, but instead sounds like other texts of a similar type. 27
Meanwhile, it becomes increasingly difficult for readers to classify such texts as either human-made or machine-generated. The extent to which we can expect to encounter generated texts in the near future becomes clear when we consider how much of the writing that surrounds us every day is such routine filler.
As more of them circulate—and they undoubtedly will—the standard expectation towards unknown texts will shift from the immediate assumption of human authorship to a creeping doubt: did a machine write this?
The stakes may seem relatively low when it comes to marketing prose—but what about the lawyer’s letter that might be automatically generated, even though it is about my own personal case? What about my students’ essays that I have to grade?28 What about political articles or fake news stories? What about the private, personal, intimate email, the love letter? Is that an AI product, too—in whole or in part?
At least one reason for the discomfort these ideas evoke is that people have a stake in what they write, and, to varying degrees, vouch for their words. Even if it a text ultimately turns out to be inaccurate or misleading, the standard expectation that a recipient brings to reading it involves the assumption that the author is making what Jürgen Habermas has called a “validity claim … to truthfulness.”29 Essentially, it means that we have a basic level of trust that speakers (writers) mean what they say. This is the reason why reading critically has to be learned at all: our first inclination is to believe texts.
This default is thrown into crisis once large language models can generate texts that appear to have been produced and sanctioned by an author, but have no reliable knowledge of the world, only of the probability distribution of tokens. This dual crisis of trust was illustrated quite drastically in November 2022 by the language model Galactica, built by the AI arm of the Facebook parent company Meta. Trained on millions of papers, textbooks, encyclopedias, and scientific websites, Galactica was supposed to help write academic texts. It was taken offline again after only three days.30
The model had dutifully composed essays that sounded authoritative, followed the conventions of scientific formatting and rhetorical gestures—but contained utter nonsense because it only completed probable sentences rather than accessing knowledge. It was predictive text pretending to be a database,31 and had merely learned the form of scientific prose, without any scientific insight, responsibility, or eventual accountability.
The Last Model and the Ouroboros
Sooner or later, the standard expectation of texts will shift—from the conviction that a human being is behind them to the doubt that it might not be a machine after all. But this will also make the distinction between natural and artificial texts increasingly obsolete. We would then possibly enter a phase of post-artificial texts.
By this I mean two related but distinct phenomena. First, “post-artificial” refers to the increasing blurring of natural and artificial text. Of course, even before large language models, no text was truly natural. Not only can the mathematical distribution of characters on a page, as Bense had in mind, also be achieved by hand,32 but it is also a truism of media studies that every writing tool, from the quill to the pens to the word processor, leaves its mark on what it produces.33
On the other hand, no text is ever completely artificial—that would require real autonomy, an actually strong AI that could ultimately decide for itself to declare a text published.34 Today, however, with AI language technologies penetrating every nook and cranny of our writing processes, a new quality of blending has been achieved. To an unprecedented and almost indissoluble degree, we are integrating artificial text with natural text. 35
For after large language models, it is not implausible that the two types of text might enter into a mutually dependent circular process that completely entangles them. Since a language model learns by being trained on large amounts of text, so far, more text always means better performance.
Thinking this through to the end, a future, monumental language model will, in the extreme case, have been trained with all available language. I call it the “Last Model.” Every artificial text generated with this Last Model would then also have been created on the basis of every natural text; at this point, all linguistic history must grind to a halt, as the natural linguistic resources for model training would have been exhausted.
This may result in what philosopher Benjamin Bratton calls the “Ouroboros Language Problem.” Like the snake that bites its own tail, all subsequent language models for further performance gain will then learn from text that itself already comes from a language model.36 Thus, one could say, natural language—even if only as a fiction that never existed anyway—would come to an end.
For the language standard thus attained would, in turn, have an effect on human speakers again—it would have the status of a binding norm, integrated into all the mechanisms of writing that build on this technology, and which would be statistically almost impossible to escape. Any linguistic innovation, any new word or grammatical quirk that might occur in human language would have such a small share in the training data that it would be averaged out and leave virtually no trace in future models.
This is, of course, a deliberately exaggerated scenario. As a thought experiment, however, it shows what post-artificial text might be in the extreme case. But even before that happens, halfway to the eschaton of absolute blending (and erasure) of natural and artificial language, a new standard expectation of unknown text might already emerge.
This is the second meaning of “post-artificial” and the one I am primarily concerned with here. After the tacit assumption of human authorship and the doubt about its origin, it would be the next expectation towards unknown texts. For doubt about the origin of a text, like any doubt, cannot be permanent; humans have an interest in establishing normality, in reducing complexity and uncertainty to a tolerable level.
This may be achieved, for example, by digital certificates, watermarks, or other security techniques designed to increase confidence that the text at hand is not just plausible nonsense.37 Or simply by banning generated text that is not declared as such.
Should political regulation and technical containment fail here, it is not unlikely that the expectation itself will become post-artificial. This means: Instead of suspecting a human behind a text, or being haunted by skepticism as to whether it was not a machine after all, the question simply becomes uninteresting: We would then focus only on what the text says, not on who wrote it. Post-artificial texts would be agnostic about their origin; they would be authorless by default.38
So if the standard expectation towards unknown text is shifting, if it is becoming more and more doubt-ridden, perhaps even disapperaing in favor of an agnostic position on authorship—why the ostentatious excitement over generated texts in literary competitions? Why is it a scandal that a novel was generated with the help of an AI when we are already enmeshed in digital technology anyway? Why could it seem as if nothing had changed, when so much is in motion?
I think because literature is slower. And this is because—Bense notwithstanding— of all text types, it makes the greatest claim to a human origin. I have already said that there are texts today whose origins do not pose a question; a street sign has no author, and in our daily life, a news site’s weather forecast is also practically authorless.
Until now, we have always assumed that a human being is behind it—but under post-artificial reading conditions nothing much changes if we simply make no assumptions at all. My expectation is that, more and more texts will soon be received in this way. Put differently: The zone of unmarked texts is expanding. Not only street signs, but also blog entries, not only weather forecasts, but also information brochures, discussions of Netflix series, and even entire newspaper articles would tend to be unmarked, apparently authorless.
Literary texts, on the other hand, are still maximally marked today. We read them very differently from other types of texts—among other things, we continue to assume that they have an author. The consequence of this markedness is that art and literature themselves have recently become the target of the tech industry—namely, as a benchmark to be usedafter other once purely human domains, such as games like chess or go, have been cracked.
Now, art and literature pose the latest yardstick: Probably nothing would prove the performance of AI models better than a convincingly generated novel. Ultimately, however, this hope is still based on the paradigm of strong deception. Indeed, there is currently a whole spate of literary and artistic Turing tests to be observed that all ask: Can subjects distinguish the real image from the artificial one, the real poem from the AI-generated one? These tests mostly come from computer science, which, as an engineering discipline, likes to have metrics to measure the success of its tasks.
The problem is that they still compare the rigid difference between natural expectation and artificial reality. This seems to me to be of little use when it is this difference itself that is at issue.39 More interesting, then, is the question of the circumstances under which this difference becomes irrelevant. In other words, what would have to happen for literature to become post-artificial?
What Is Post-Artificial Literature? And What Isn’t?
I will answer this question by returning once again to the standardization tendency that arises from the ouroboros effect of large language models. In them, as I said, normalization takes place. Their outputs are most convincing precisely when they spit out what is expected, what is ordinary, what is statistically probable. And just as marketing AIs now assist in the creation of marketing prose that meets our expectations, there are also literature AIs that assist in writing “expectable” literature.
“Expectability” can be described statistically as a probability distribution over a set of elements—the more recurrent they are, the more likely and expectable the outcome. Genre literature is virtually defined by the recurrence of certain elements, making it particularly suitable for AI generation.
For example, the website The Verge reported on the author Jennifer Lepp, who writes fantasy novels under the pseudonym Leanne Leeds—like an assembly line, one every 49 days.40 She is aided by the program Sudowrite, a GPT-3-based literary writing assistant that continues dialogues, adds descriptions, rewrites entire paragraphs, and even provides feedback on human writing. The quality of this output is quite high, insofar as their content is expectable. Since all idiosyncrasies are averaged out in the mass of training data, they tend toward a conventional treatment of language—they become ouroboros literature themselves.
At the moment, machine learning is not yet mature enough to generate entire novels, but I do not see why just this kind of literature could not be produced in an almost fully automated way very soon; then it would be possible to reduce the 49 days to 49 minutes, or even less. If the prediction is allowed: I think it would be this kind of literature that is most likely to become post-artificial.
Of course, author names would not disappear; but they would function more as brands, representing a particular, tested style, rather than actually indicating human origins. The unmarked zone would extend to certain areas of literature—not all, and certainly not all narrative, but far more than it does today.
Conversely, one might ask: What kind of literature is most likely to escape this expansion? Here I see two, at first glance, contradictory answers. If the unmarked, post-artificial literature is one that absolutely mixes natural and artificial poetry, further marked writing would be one that emphasizes their separation.
On the one hand, then, one could imagine the emphasis on human origins as a special feature. Negatively, we can already observe phenomena that point to such a development. On the web, for example, artists are up in arms against image-generating AI such as Dall-E 2 or Stable Diffusion.
They recognize stylistic features of their own work in the generated output, which may therefore have been part of the training set; this raises legitimate questions about copyright and fair compensation.41 At the same time, however, there is also resistance to AI-generated art per se, which, some fear, threatens to make human artists obsolete.
On Twitter, the hashtag #supporthumanartists has emerged as a declaration of war against generative image AI.42 One can imagine something similar for literature, perhaps even a future in which the label guaranteed human-made could be considered a distinction. Just as one buys handmade goods on Etsy, a kind of boutique writing would be conceivable that carries its human origin in front of it as a proof of quality and a selling point.
But if one does not want to rely solely on the assurance of human origins—which in any case still leave room for doubt—an unpredictable, unconventional use of language can indicate writing beyond the model’s abilities. Every formal experiment, every linguistic subversion would oppose the probability of great language models, their leveling ouroboros standard; linguistic unpredictability would then be evidence of human origin.

In the most extreme case, the sign system in which language AIs operate would be exploded—as in the case of visual and “asemic” literature, say, in the works of Kristen Mueller: She no longer uses any letters at all, but only the impression of lines and blocks of text.43 The pure poetry Max Bense dreamed of would paradoxically not come from the machine, which now, in post-artificial blending, plausibly simulates meaning, but from people who no longer attempt to create it.
In that sense, and this is the second route of highlighting a text as non-AI-made, the descendants of Lutz and Bense at least have a chance of escaping the post-artificial by continuing to mark the artificiality of their products. This is digital literature—literature that is self-reflexively produced with the help of computers. It can escape the post-artificial by consciously emphasizing the entanglement between the natural and the artificial rather than glossing it over for a “natural-seeming” appearance. Much more than conventional writing, digital literature always keeps a critical eye on its origins.44
I have written about this in much greater detail elsewhere, and will give just two examples here: One is Mattis Kuhn’s book Selbstgespräche mit einer KI (Monologues with an AI), in which, in addition to his literary experiments, he also provides the source code for training the language model and even its database; the human and machine components that together produce in the text can—not completely, but at least somewhat—be separated here.
Conversely, a deliberately staged human-machine collaboration can also have this analytical effect: In David “Jhave” Johnston’s ReRites, for example, the author trained a language model every night for a year and then edited the output by hand the next morning in a process he calls “carving.” The point at which the machine hands over its text to the human Jhave is precisely marked. And by collecting the edited results of each month in a book—so that ReRites now comprises twelve heavy volumes—he also frames this collaborative but not absolutely fused process as a performance, which is also not conventionally literary.
Of course, here, too, no “proof” of human intervention is ultimately provided. But perhaps the obstacles that can still be placed in the way of the all too smooth reception process are the maximum of resistance to the post-artificial that is still possible – before the difference between natural and artificial has really disappeared altogether.
*
It should have become clear that I have entered highly speculative territory here. I am not suggesting that narrative or, broadly speaking, conventional literature is doomed from now on, and that we should only pursue experimental or explicitly digital literature. Nor that post-artificial texts are necessarily bad—one can certainly enjoy reading them, discuss their merits, and unravel their interpretive dimensions.
Here, I have been primarily interested in analyzing tendencies, and for this purpose it is worthwhile to consider possible extremes. Above all, I wanted to try to think about how language is changing in that technical age we inhabit today and which will continue to unfold—both without being afraid of technology, but also without succumbing to its ideologies. In any case, one thing seems certain to me: With the increasing penetration of language technologies, with the triumph of AI models, our reading expectations will change.
So here is a final question for you: How do you react when I now tell you that I, too, have had large parts of this text written by AI? Do you feel deceived? Then you are still firmly at home in the standard expectation of the twentieth century. But I can reassure you: This text was written without any AI assistance. Or was it? Can you be quite sure of that? If you are now undecided, then you are already on the threshold of the second expectation, the doubt about the origin of a text in the age of great language models. Or perhaps you are indifferent—maybe not completely, but at least to the extent that you can imagine what a world of post-artificial texts might look like.
- Max Bense, “Über natürliche und künstliche Poesie,” in Theorie der Texte: Eine Einführung in neuere Auffassungen und Methoden (Köln: Kiepenheuer & Witsch, 1962), 143.
- Bense, 143. I interpret Bense as articulating an early (ontological) version of the symbol grounding problem, but linking it (provocatively) to a post-Romantic poetics, which serves as a negative foil to his avant-garde aesthetics. See Stevan Harnad, “The Symbol Grounding Problem,” Physica D: Nonlinear Phenomena 42, no. 1–3 (1990): 335–46.
- See Kurt Beals, “‘Do the New Poets Think? It’s Possible’: Computer Poetry and Cyborg Subjectivity,” Configurations 26, no. 2 (2018): 149–77.
- Theo Lutz, “Stochastische Texte,” Augenblick 4, no. 1 (1959): 3–9.
- Instead—and this can be observed in many early experiments with such generative literature—their creators almost always saw themselves as authors and assigned the computer only the role of a tool, see Hannes Bajohr, “Autorschaft und Künstliche Intelligenz,” in Handbuch Künstliche Intelligenz und die Künste, ed. Stephanie Catani and Jasmin Pfeiffer (Berlin: de Gruyter, forthcoming).
- electronus [i.e. Theo Lutz], “und kein engel ist schön,” Ja und Nein 12, no. 3 (1960): 3.
- “So reagierten Leser,” Ja und Nein 13, no. 1 (1961): 3. I thank Toni Bernhart for sharing this finding with me; for the background, see Toni Bernhart, “Beiwerk als Werk: Stochastische Texte von Theo Lutz,” Editio, no. 34 (2020): 180–206.
- This is very similar to Leah Henrickson’s notion of the “hermeneutic contract”. However, I contend that this contract implies that the instance writing is specifically human. See Leah Henrickson, Reading Computer-Generated Texts (Cambridge: Cambridge University Press, 2021), 28.
- Alan M. Turing, “Computing Machinery and Intelligence,” Mind 59, no. 236 (1950): 433–60.
- Turing takes this setup from the “imitation game,” in which the gender of the unknown person is to be guessed. Much has been made of this “passing,” both in terms of Turing’s own biography—as a gay man he was forced to undergo estrogen treatment, to which his suicide is probably related—and the gendered nature of AI more generally as the “obvious connection between gender and computer intelligence: both are in fact imitative systems, and the boundaries between female and male, I argue, are as unclear and as unstable as the boundary between human and machine intelligence.” Jack Halberstam, “Automating Gender: Postmodern Feminism in the Age of the Intelligent Machine,” Feminist Studies 17, no. 3 (1991): 443.
- The essential textuality of AI was already pointed out by Jay David Bolter in 1991: “Artificial intelligence is the art of making texts,” Jay David Bolter, “Artificial Intelligence,” in Writing Space: The Computer, Hypertext, and the History of Writing (Hillsdale, NJ: Erlbaum, 1991), 180.
- Simone Natale, Deceitful Media: Artificial Intelligence and Social Life after the Turing Test (Oxford: Oxford University Press, 2021), 3. Emphasis mine.
- Kevin Roose, “An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy,” The New York Times, September 2, 2022.
- Danny Lewis, “An AI-Written Novella Almost Won a Literary Prize,” Smithsonian Magazine, March 28, 2016.
- @horse_ebooks, June 28, 2012.
- @horse_ebooks, July 25, 2012.
- Memphis Barker, “What Is Horse_ebooks? Twitter Devastated at News Popular Spambot Was Human After All,” The Independent, September 24, 2013.
- I use the term “authorship” here in a deliberately reductive way. I do not mean the “mode of being of discourse” and the “classificatory function” of work coherence and intellectual property, for which the concept of authorship is usually reserved in its emphatic function, Michel Foucault, “What Is an Author?,” in Aesthetics, Method, and Epistemology, ed. James D. Faubion (New York: New Press, 1998), 211, 210. Instead, I assume a “causal” authorship (who produced this text and by what means?, see Bajohr, “Autorschaft und Künstliche Intelligenz”) and ask about the reception-side awareness of this causality. My usage is thus of a lesser breadth than the “implicit author,” which is also an artifact of the text, and thus cannot be resolved simply by a general notion of text.
- Natale, Deceitful Media, 4.
- I am not engaging with systems theory here, which focuses solely on the concept of communication and deliberately excludes “human origins.” This perspective is nicely described in Elena Esposito, Artificial Communication: How Algorithms Produce Social Intelligence (Cambridge, Massachusetts: The MIT Press, 2022).
- John Seabrook, “The Next Word. Where Will Predictive Text Take Us?,” The New Yorker, October 4, 2019.
- The matter is more complicated than this; there is such a thing as “dumb meaning” in AI models, which I explain in Hannes Bajohr, “Dumb Meaning: Machine Learning and Artificial Semantics“, Research Gate Working Paper.
- See ibid.
- GPT-3, “A Robot Wrote This Entire Article. Are You Scared yet, Human?,” September 8, 2020. That GPT-3 figures as the author is a fiction, of course. As a disclaimer at the end of the article points out, the outputs were hand-selected; the prompts fed to the program came from a computer science student named Liam Porr. And it is worth pointing out the obvious: that the pronoun “I” has little more significance in a language model than the word “umbrella”—it is a category mistake to read the one as a statement of identity or the other as a reference to an object in the world.
- But only slightly. The general enthusiasm about and subsequent disenchantment with ChatGPT simply caught up with the experience those who had beta access to GPT-3. It will be more interesting when GPT-4 comes out later this year (but do not hold your breath).
- See Hannes Bajohr, “The Paradox of Anthroponormative Restriction: Artistic Artificial Intelligence and Literary Writing,” CounterText 8, no. 2 (August 2022): 262–82.
- Just one example among many: “Jasper—AI Copywriting & Content Generation for Teams,” accessed December 14, 2022.
- The discussion about the use of ChatGPT for school and college assignments has, interestingly enough, garnered the most attention in the popular discussion of large language models. This is astonishing insofar as the admission of operating a test regime based on predictable language should perhaps put this regime itself to the test. The expected arms race between language model and language model detection is in any case hardly conducive to pedagogical practice. (The measure recently reported from a New York school—it had summarily blocked the IP address for ChatGPT on school computers—seems symptomatically helpless, and certainly not on par with students’ ingenuity in circumventing such measures.) With respect to the longue durée of possible post-artificial texts that I am dealing with here, the frequently-made argument that we are now experiencing the transition from the slide rule to the calculator, but for the humanities rather than math, seems plausible to me.
- Jürgen Habermas, The Theory of Communicative Action, trans. Thomas McCarthy, vol. 1 (Boston: Beacon, 1981), 52.
- Will Douglas Heaven, “Why Meta’s Latest Large Language Model Survived Only Three Days Online,” MIT Technology Review, November 18, 2022. For this reason, a lot still has to happen technically for ChatGPT to really be used as a reliable search engine.
- Murray Shanahan describes the difference succinctly: “Suppose we give an LLM the prompt ‘The first person to walk on the Moon was ‘, and suppose it responds with ‘Neil Armstrong.’ What are we really asking here? In an important sense, we are not really asking who was the first person to walk on the Moon. What we are really asking the model is the following question: Given the statistical distribution of words in the vast public corpus of (English) text, what words are most likely to follow the sequence ‘The first person to walk on the Moon was’? A good reply to this question is ‘Neil Armstrong’.” Murray Shanahan, “Talking About Large Language Models” (arXiv, December 11, 2022), 2, http://arxiv.org/abs/2212.03551.
- Tobias Wilke, “Digitale Sprache: Poetische Zeichenordnungen im frühen Informationszeitalter,” ZfL Blog, November 12, 2021.
- See Martin Stingelin, “UNSER SCHREIBZEUG ARBEITET MIT AN UNSEREN GEDANKEN. Die poetologische Reflexion der Schreibwerkzeuge bei Georg Christoph Lichtenberg und Friedrich Nietzsche,” in Schreiben als Kulturtechnik: Grundlagentexte, ed. Sandro Zanetti (Berlin: Suhrkamp, 2012), 83–104.
- See Bajohr, “The Paradox of Anthroponormative Restriction.”
- This meaning of “post-artificial” seems at first glance to be based on the term “post-digital”. But while the latter focuses primarily on the difference between digital and analog technologies—which may already be automated—the former is primarily concerned with the human or non-human origin of an artifact, regardless of its specific technical substrate.
- Benjamin Bratton and Blaise Agüera y Arcas, “The Model Is The Message,” Noema, July 12, 2022.
- OpenAI already offers one such a solution: “AI Text Classifier,” accessed February 3, 2023. A future solution might involve embedding a specific watermark in AI-generated output: Since the distribution of the output words (or tokens) is not actually random, but follows a pattern that only appears to be arbitrary, a specifically produced distribution may serve as a watermark. Of course, all that would be needed is for a second, less sophisticated AI to be tasked with reformulating the output of the first, and that watermark would be erased, see Kyle Wiggers, “OpenAI’s Attempts to Watermark AI Text Hit Limits,” TechCrunch, December 10, 2022.
- What Foucault had already imagined in the sixties would finally have occurred: the question of authorship would have been lost in the “anonymity of a murmur,” Foucault, “What Is an Author?,” 222.
- When one such study writes, “the best way of how human performance should be enhanced by means of AI is by using AI in terms of sets of tools that enable humans themselves to become more creative or productive,” the rhetoric of “enhancing” natural abilities is incapable of reflecting on the essentially mixed nature of future text, Vivian Emily Gunser et al., “Can Users Distinguish Narrative Texts Written by an Artificial Intelligence Writing Tool from Purely Human Text?,” in HCI International 2021—Posters, ed. Constantine Stephanidis, Margherita Antona, and Stavroula Ntoa, vol. 1419 (Cham: Springer, 2021), 521.
- Josh Dzieza, “The Great Fiction of AI: The Strange World of High-Speed Semi-Automated Genre Fiction,” The Verge, July 20, 2022.
- For example, comic artist Sarah Andersen describes how her own work was part of the training set for Stable Diffusion, which can now output images in her style. The name of the artist is thus “no longer attached to just his own work, but it also summons a slew of imitations of varying quality that he hasn’t approved. … I see a monster forming.” Sarah Andersen, “The Alt-Right Manipulated My Comic. Then A.I. Claimed It,” The New York Times, December 31, 2022.
- A list of artists who decidedly do not work with AI can be found at https://whimsicalpublishing.ca/support-human-artists (as of 7.1.2023).
- Kristen Mueller, Partially Removing the Remove of Literature (New York: & So., 2014). Of course, an image AI could reproduce her works easily.
- See Hannes Bajohr and Annette Gilbert, “Platzhalter der Zukunft: Digitale Literatur II (2001 → 2021),” in Digitale Literatur II, ed. Hannes Bajohr and Annette Gilbert (München: edition text+kritik, 2021), 7–21. I discuss the examples mentioned here in more depth in Hannes Bajohr, “Künstliche Intelligenz und Digitale Literatur: Theorie und Praxis konnektionistischen Schreibens,” in Schreibenlassen: Texte zur Literatur im Digitalen (Berlin: August Verlag, 2022), 191–213.
Leave a Reply